In the previous post I gave a summary of the problem to be solved using the Successful Module. I explained that in fact the problem is solved using a Successful Module Framework (SMF) and Successful Module Instances SM(i). The SMF is a library used by the client application (CA) and the SM(i) to interact with each other without building cumbersome circular references and dependencies. In Java all modules are .jar files. At compile time both the CA and the SM(i) know the SMF but they don't know each other. Of course at runtime the CA needs to know how to load the SM(i) but that information is limited to the file location. Once it is loaded the CA interacts with the SM(i) as if it consisted only of classes (more precisely interfaces) defined in the SMF.
The CA loads the SM(i) .jar and looks for a class that implements an interface called IInstrumentDefinition that marks it as the point of entry into the module. In fact the CA knows only interfaces (pure abstract classes in C++) defined in the SMF. This is one of the key to the success of the whole project. No concrete classes in the API. To understand what the IInstrumentDefinition is we need to enumerate some of the interaction between the CA and an analyzer. The CA needs to:
1- Define the value of parameters used by the analyzer (resolution, number of scan, etc...)
2- Find the list of values that a particular analyzer can supply (the data it can return, etc...)
3- Start an acquisition
4- Read the status of the analyzer
5- Read the data at the end of an acquisition cycle
So. Does the IInstrumentDefinition need to supply operations (methods) related to all these interactions ? No, not at all.
In fact it turns out that many of the operations listed above are defined in a separate class called an IInstrument. Things like operation 3, 4 and 5 are defined in the IInstrument. We found that in practice it was very useful to have a specific interface - the IInstrumentDefinition - to define the functions that would provide the more "static" information about an analyzer and that it made sense that this interface be the entry point into the module. We also identified another very important function of the IInstrumentDefinition: Abstract Factory.
The instrument definition is a factory for a host of classes used when interacting with a specific analyzer. Of course the most important of the factory method is the getInstrument() method that returns a IInstrument.
Saturday, May 11, 2013
Saturday, April 27, 2013
Good software design principles part 2
For the benefit of this blog we will call the module mentioned in the previous post the SM for successful module. Remember that the objective for this module was to make our software capable of acquiring and analysing data from any third party instrument. When thinking about a problem like this many of you might immediately think about the Open Close Principle. If you did not think about this and/or if you do not know what the OCP is, here is a definition:
Trying to satisfy the OCP has a number of implication. One of them is that you should not have to modify the application code each time you want to support a new instrument. So of course the first thing that was decided was that the module should be loaded dynamically at runtime based on information in the application configuration. This is not earth shattering or revolutionary but it is a very useful concept. What we will be doing with the SM is to build a plugin infrastructure for our application instrument interface. Plugin are used in Eclipse, Netbeans and a whole menagerie of applications. In Java this is easy to do you just pack your SM in a .jar. Now the tricky par is to define the API that this jar file should implement. Another more immediate task is to define how the whole thing will be structured in terms of module. Now from the discussion we know that the starting point is this:

Now with a project like this you want to get your dependencies right from the beginning. In the case of this project it is easy to understand that has illustrated on the diagram communication between the two module goes both way. The Application supplies the SM with parameters and possibly other information and the SM returns statuses and results to the Application. We will probably need to allocate objects and possibly implement interfaces on the application side as well as in the SM. The question then is: where do we define those classes and interfaces ? The answer is: in a third module. Now the high level view of the project looks like this:

Now except for the weird looking arrow the elements on that diagram are packages with their dependencies. You have:
1) Application.
2) SM(I). This is a specific SM Instance (I added the I between parentheses to highlight that).
3) SMF the Successful Module Framework
As you can see there is no circular dependency in the standard UML elements. At compile time the APplication depends only on the SMF and the SM(I) also knows only the SMF. Now I added a non UML element (the weird broken arrow not quite connected) to represent the runtime dependencies in the system. I think having this extra arrow makes everything obvious and clean. In my next blog entry we will continue on our analysis of the SM and SMF. In fact for a while the emphasis will turn on the SMF and the key patterns used in that module the most important being:
- Abstract Factory
- Strategy
Now a closing comment. It goes without saying that before you start on a project like this a good analysis and requirements definition phase is in order. This is beyond the scope of the current thread but we might come back to this or insert a few blog entries about this phase later.
software entities (classes, modules, functions, etc.) should be open for extension, but closed for modificationHere is a link to the Wikipedia article: OCP
Trying to satisfy the OCP has a number of implication. One of them is that you should not have to modify the application code each time you want to support a new instrument. So of course the first thing that was decided was that the module should be loaded dynamically at runtime based on information in the application configuration. This is not earth shattering or revolutionary but it is a very useful concept. What we will be doing with the SM is to build a plugin infrastructure for our application instrument interface. Plugin are used in Eclipse, Netbeans and a whole menagerie of applications. In Java this is easy to do you just pack your SM in a .jar. Now the tricky par is to define the API that this jar file should implement. Another more immediate task is to define how the whole thing will be structured in terms of module. Now from the discussion we know that the starting point is this:

Now with a project like this you want to get your dependencies right from the beginning. In the case of this project it is easy to understand that has illustrated on the diagram communication between the two module goes both way. The Application supplies the SM with parameters and possibly other information and the SM returns statuses and results to the Application. We will probably need to allocate objects and possibly implement interfaces on the application side as well as in the SM. The question then is: where do we define those classes and interfaces ? The answer is: in a third module. Now the high level view of the project looks like this:

Now except for the weird looking arrow the elements on that diagram are packages with their dependencies. You have:
1) Application.
2) SM(I). This is a specific SM Instance (I added the I between parentheses to highlight that).
3) SMF the Successful Module Framework
As you can see there is no circular dependency in the standard UML elements. At compile time the APplication depends only on the SMF and the SM(I) also knows only the SMF. Now I added a non UML element (the weird broken arrow not quite connected) to represent the runtime dependencies in the system. I think having this extra arrow makes everything obvious and clean. In my next blog entry we will continue on our analysis of the SM and SMF. In fact for a while the emphasis will turn on the SMF and the key patterns used in that module the most important being:
- Abstract Factory
- Strategy
Now a closing comment. It goes without saying that before you start on a project like this a good analysis and requirements definition phase is in order. This is beyond the scope of the current thread but we might come back to this or insert a few blog entries about this phase later.
Saturday, April 20, 2013
Good software design principles and weekends at the beach
I work on software that is used to read and analyse data from instruments made by the company I work for: Fourier Transform Infrared Spectrometer. The software I work on is a client/server type continuous acquisition and analysis software. I work on the server component of that software.
One key component used by the server is the data acquisition component - sometimes called the data acquisition driver. These days data acquisition module is a more appropriate name for it since this component is written in Java and does not really corresponds to what we would call a driver. In the old days, when our software was written in C/C++ the thing really was a driver. However, in recent years the link between the PC and our instrument was changed from a proprietary protocol to good old Ethernet TCP/IP link. Also, in the meantime, software development switched to Java. Of course, all of this is very nice since Java has very good Network communication libraries.
Now, our software is very flexible and has very good data processing capabilities so why not use it to analyse data from other instruments ? Well that's exactly what I was asked to do a few years ago: make our software capable of acquiring and analysing data from any third party instrument. Now, while this may sound like a simple task, doing it right really is not that simple.
In my next few blog entries I'm going to talk about how this problem was solved. Now of course, I'm not going to discuss this at a level of details that could get me in trouble with my employer but this is not a problem since the key to the success of the project are not in the kind of implementation details that could be considered trade secret. No actually the key to the success of this project was using well known and documented good software design principles. I think you will enjoy this.
One key component used by the server is the data acquisition component - sometimes called the data acquisition driver. These days data acquisition module is a more appropriate name for it since this component is written in Java and does not really corresponds to what we would call a driver. In the old days, when our software was written in C/C++ the thing really was a driver. However, in recent years the link between the PC and our instrument was changed from a proprietary protocol to good old Ethernet TCP/IP link. Also, in the meantime, software development switched to Java. Of course, all of this is very nice since Java has very good Network communication libraries.
Now, our software is very flexible and has very good data processing capabilities so why not use it to analyse data from other instruments ? Well that's exactly what I was asked to do a few years ago: make our software capable of acquiring and analysing data from any third party instrument. Now, while this may sound like a simple task, doing it right really is not that simple.
In my next few blog entries I'm going to talk about how this problem was solved. Now of course, I'm not going to discuss this at a level of details that could get me in trouble with my employer but this is not a problem since the key to the success of the project are not in the kind of implementation details that could be considered trade secret. No actually the key to the success of this project was using well known and documented good software design principles. I think you will enjoy this.
Thursday, April 18, 2013
Eclipse vs Netbeans ... no contest
Everyone is crazy about Eclipse. Me, I just can't stand Eclipse any more. Version 4.x was supposed to bring working multiple editor window but it just is not working. If you use a second editor window (drag an editor tab on a separate screen) the shortcut keys do not work and operations selected in the menu are simply not applied to the correct screen. I don't need billions of plugin. I need a working editor and just like I can't stand single pane file browsers I simply can't stand an editor that does not properly support multiple separate editor window. I spend most of my time editing code so I'm going back to good old clean and stable Netbeans. Which Java IDE should you use ? Well Netbeans of course.
Sunday, January 22, 2012
Writing good static argument validation methods
Before we get into the NullObjectProxy class there is one more prerequisite to get out of the way.
How many times did you have to write the following kind of code:
 Here is the getFormattedMessage(..) method:
Here is the getFormattedMessage(..) method:
 Now with this version what you have on each call is that a few arguments are pushed on the stack. You still have annoying side effects though. You still get an Object[] allocated and filled on each call. Also, if you have primitive arguments you get autoboxing of those into primitive wrapper classes (Integer, FLoat, ...). Of course you can further optimize this by having different versions of the method with different primitive arguments. Fortunately it is easy to define such methods for the most common cases. Here is an example with two int arguments:
Now with this version what you have on each call is that a few arguments are pushed on the stack. You still have annoying side effects though. You still get an Object[] allocated and filled on each call. Also, if you have primitive arguments you get autoboxing of those into primitive wrapper classes (Integer, FLoat, ...). Of course you can further optimize this by having different versions of the method with different primitive arguments. Fortunately it is easy to define such methods for the most common cases. Here is an example with two int arguments:
I was so pleased with this that I added a validateNotNull(boolean, String, Object ...) method:
Ok, now your thinking "that's a lot of trouble for an assert mechanism". The reason I don't use the Java assert mechanism for this is that:
1) I don't want it to be possible to disable those verifications and I want them enabled by default.
2) My Verification class methods have a very usefull trace mechanism build-in. When activated this trace will always get printed even if exceptions are thrown away or lost (handled improperly in thread, ...).
I really like those little methods and I use them a lot. They make it really easy to build meaningful error information reporting into the code.
Of course I will use them in my next blog about my new NullObjectProxy class.
How many times did you have to write the following kind of code:
// Example (1)
if (parameter > limit)
{
throw new IllegalArgumentException (
"'parameter' is too large: " + parameter + " > " + limit);
}
I decided that I had enough of this and that I wanted to be able to write something like:// Example (2) validate (parameter > limit, "'parameter' is too large: " + parameter + ">" + limit);However, a little thinking made me realize that this form is not really appropriate and would have annoying side effects. In this specific case a bunch of Strings would be allocated and concatenated each time the method is called and that is not good since it would make calling the method very different from the initial code. I did a little more thinking and I came up with:
// Example 3 validate (parameter > limit, "'parameter' is too large: &1 > &2", parameter, limit);The implementation for this is shown below:

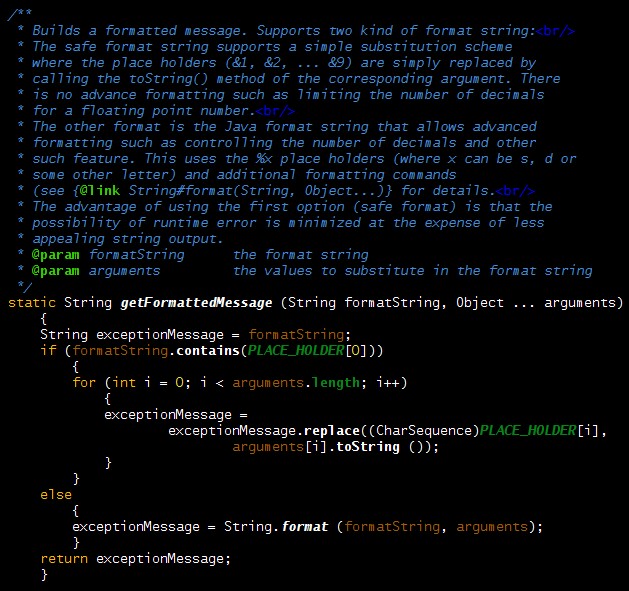
public static final void validate (boolean condition, String formatString,
int firstValue, int secondValue)
Those methods are defined in a static utility class called Verification and this class contains one and two arguments versions for all primitive number types. Now, the validationFailure(String, Object ...) is called only if the condition fails and so objects are allocated only on failures. We at last have something close enough to the original construct that we can use on a routine basis.I was so pleased with this that I added a validateNotNull(boolean, String, Object ...) method:
// Example (4a) public static <T> T validateNotNull (T value, String formatString, Object ... arguments)This is a generic method that will handle any type of reference and return the correct type (no cast needed). I also have a short form for this:
// Example (4b) public static <T> T validateNotNull (T value, String parameterName)This short form will print a predefined message:
parameterName should not be nullYou can use those methods like this (short form):
// Example (5) SomeType localVariable = validateNotNull (parameterOfSomeType, "parameterOfSomeType");The verification class also contains a number of expect(boolean, String), expect(boolean, String, Object ...) and expectNotNull(Object, String) methods. Those are used to test other conditions that would normally throw IllegalStateExceptions.
Ok, now your thinking "that's a lot of trouble for an assert mechanism". The reason I don't use the Java assert mechanism for this is that:
1) I don't want it to be possible to disable those verifications and I want them enabled by default.
2) My Verification class methods have a very usefull trace mechanism build-in. When activated this trace will always get printed even if exceptions are thrown away or lost (handled improperly in thread, ...).
I really like those little methods and I use them a lot. They make it really easy to build meaningful error information reporting into the code.
Of course I will use them in my next blog about my new NullObjectProxy class.
Wednesday, December 28, 2011
When is it ok to use method overloading in Java ?
In his excellent book Efficient Java Programming, Joshua Bloch has an item titled:
Lets look at a few examples. We will base those examples on the set of classes illustrated here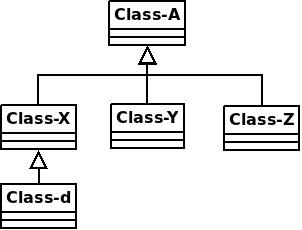 We will use a one parameter method as our existing method to overload: m(Class-X x1)
We will use a one parameter method as our existing method to overload: m(Class-X x1)
The following overloaded versions would be ok:
m(Class-Y x1)
m(Class-Z x1)
The following would not be ok:
m(Class-A x1)
m(Class-d x1)
Had the original method been m(Class-A x1) there would have been no safe way to overload using the types in the diagram.
Had the original method been m(Class-d x1) then the following overloaded versions would have been ok:
m(Class-Y x1)
m(Class-Z x1)
But m(Class-A x1) or m(Class-X x1) would not be safe.
You get the idea.
Item 41: Use overloading judiciouslyBecause I'm going to use method overloading in my NullObjectProxy implementation I will give some additional information about when it is ok to use method overloading. I highly recommend that you read Item 41 but here is a little extra graphic help and also a relaxation of Joshua Bloch's criteria. To simplify the presentation I will assume that the return type of all methods here is void and I will not include the return type in the examples. For a method m(t1 x1, t2 x2, ..., tn xn) where t1 to tn are the n parameter types it is safe to create an overloaded version m(t'1 x1, t'2 x2, ..., t'n xn) if for each type ti (i=1 to n), t'i is not a subtype or supertype of t.
Lets look at a few examples. We will base those examples on the set of classes illustrated here

The following overloaded versions would be ok:
m(Class-Y x1)
m(Class-Z x1)
The following would not be ok:
m(Class-A x1)
m(Class-d x1)
Had the original method been m(Class-A x1) there would have been no safe way to overload using the types in the diagram.
Had the original method been m(Class-d x1) then the following overloaded versions would have been ok:
m(Class-Y x1)
m(Class-Z x1)
But m(Class-A x1) or m(Class-X x1) would not be safe.
You get the idea.
Saturday, December 24, 2011
Learning from experience
Since my last post I have had several occasions of using my NullObjectProxy class in practice. I learned a lot from that. The first thing I realized was that I needed to allow defining behavior for the Object class methods (hashCode, equals, toString). Used in the confined environment of unit tests this was not obvious but used in real code it really became evident that this was needed. In fact I decided that I needed to provide a default coherent behavior for those methods.
I also realized that I needed to provide a more sophisticated method of defining return value even for a Null object.
The result of all this was that I modified my initial code quite a bit. So in my next post I am going to start over on the NullObjectProxy and used the updated more sophisticated version of this class.
I also realized that I needed to provide a more sophisticated method of defining return value even for a Null object.
The result of all this was that I modified my initial code quite a bit. So in my next post I am going to start over on the NullObjectProxy and used the updated more sophisticated version of this class.
Subscribe to:
Posts (Atom)
